-
La identidad digital incluye datos, credenciales y comportamientos en línea.
-
Cada clic, búsqueda o compra deja una huella digital que te representa.
-
La identidad digital se ha convertido en un activo económico estratégico.
-
Sistemas centralizados crean riesgos de censura, filtraciones y abuso de datos.
-
La identidad autosoberana busca que tú controles tus datos y credenciales.
Table of Contents
Nuestra identidad digital se ha convertido en un recurso estratégico que grandes empresas y gobiernos controlan y monetizan. Cada interacción en línea contribuye a un perfil que puede ser analizado, compartido y explotado, afectando desde la publicidad que recibimos hasta el acceso a servicios esenciales. Comprender cómo se forma nuestra identidad digital y los riesgos asociados es clave, para recuperar control y autonomía en el entorno conectado.
1 La identidad digital: quiénes somos cuando estamos conectados
Una identidad digital es el conjunto de información que identifica, representa y autentica a una persona, organización o dispositivo en el entorno digital. Incluye atributos verificables, señales de comportamiento, credenciales y otras huellas que permiten distinguir a un individuo dentro de sistemas y servicios en línea.
Sin embargo, no se trata únicamente de un perfil en una red social o una cuenta de correo: es una colección continua de datos —desde tu nombre de usuario hasta tu historial de actividad— que en conjunto pueden autenticarte, predecir patrones o incluso segmentarte para publicidad.
Cada vez que navegas, publicas, das “me gusta”, compras o incluso buscas información, generas señales que forman parte de tu identidad digital. Este rastro, llamado huella digital (digital footprint), incluye tanto actividades que realizas conscientemente como aquellas que dejas pasar inadvertidas (cookies, tiempo de navegación, ubicaciones geográficas, etc.).
Estas acciones aparentemente triviales pueden ser analizadas por algoritmos para inferir rasgos como preferencias, intereses y riesgos asociados a tu perfil, incluso si nunca los declaraste explícitamente.
Dato curioso: ¿Cuál fue la primera identidad digital registrada?
Curiosamente, la primera forma reconocible de identidad digital registrada no surgió con Internet ni con las redes sociales, sino con los sistemas informáticos multiusuario de los años 60. En particular, el Compatible Time-Sharing System (CTSS) desarrollado en el MIT introdujo cuentas de usuario con identificadores únicos, contraseñas, permisos y registros de actividad, permitiendo distinguir y autenticar a distintas personas dentro de una misma computadora.
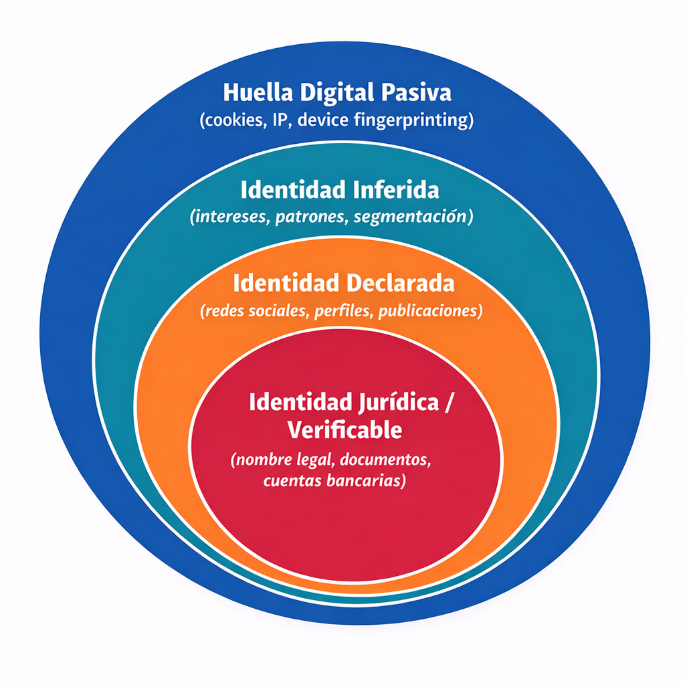
Tipos de identidad digital: declarada, inferida y registrada
Entender los distintos componentes de una identidad digital ayuda a explicar cómo “se arma” una representación en línea:
- Identidad declarada: es la información que tú mismo escoges compartir explícitamente; tu nombre, biografía de redes sociales, fotografías, publicaciones y datos personales que introduces en formularios o perfiles.
- Identidad inferida: resulta de análisis algorítmico sobre tus acciones y hábitos. Por ejemplo, si pasas mucho tiempo leyendo artículos sobre un tema, los sistemas pueden deducir intereses, afinidades y características demográficas que no has compartido de forma directa.
- Identidad registrada: se refiere a los datos que quedan almacenados en plataformas, servidores o bases de datos como resultado del uso de servicios digitales. Estos pueden incluir registros de acceso, cookies, direcciones IP o historiales de transacciones. En muchos casos, su recopilación se realiza bajo formas de consentimiento implícito —como la aceptación de términos y condiciones— o en cumplimiento de obligaciones técnicas y legales.
Aunque este almacenamiento no es necesariamente ilegal, suele ser opaco para el usuario, que tiene un control limitado sobre cómo se conservan, procesan o reutilizan estos datos a lo largo del tiempo.

Identidades digitales múltiples y coexistencia en paralelo
Aunque lo intenta ser en esencia, en la práctica la identidad digital no es una entidad única ni estable, sino un conjunto fragmentado de representaciones que una misma persona mantiene de forma simultánea en distintos entornos digitales. Estas representaciones pueden coexistir sin necesidad de integrarse entre sí y responden a lógicas, finalidades y grados de exposición diferentes.
Desde una perspectiva académica, esta multiplicidad se explica por la contextualidad de la identidad: los atributos que un individuo activa en línea dependen del sistema, la audiencia y la función para la cual esa identidad es utilizada. Así, una persona puede operar con una identidad verificable y asociada a su nombre legal en entornos institucionales o profesionales, mientras que adopta identidades seudónimas o parcialmente anónimas en espacios sociales, culturales o recreativos, sin que ello implique contradicción ni incoherencia entre unas y otras.
Este fenómeno ha sido documentado en estudios sobre identidad digital, que distinguen entre identidades persistentes (vinculadas a registros oficiales, contratos o servicios financieros) e identidades situacionales (creadas para interactuar en plataformas específicas, comunidades en línea o redes sociales). Cada una de ellas produce y acumula datos distintos, deja huellas propias y está sujeta a mecanismos de control, vigilancia y gobernanza diferentes.
En este sentido, la identidad digital puede entenderse como una arquitectura de capas, donde cada capa responde a un marco normativo, técnico y social particular. Algunas capas están fuertemente reguladas y ancladas a la identidad jurídica de la persona, mientras que otras ofrecen mayor flexibilidad, opacidad o separación respecto del individuo físico. Esta estratificación no solo afecta la forma en que una persona se presenta en línea, sino también cómo es observada, clasificada e interpretada por sistemas algorítmicos y plataformas digitales.
2 ¿Qué es la huella digital y qué rastros dejamos en la red?
La huella digital hace referencia al conjunto de datos que una persona genera —de forma voluntaria o involuntaria— como resultado de su interacción con sistemas digitales. Este rastro no es un subproducto accidental de la vida en línea, sino uno de los elementos centrales sobre los que se construye la identidad digital, ya que permite observar, clasificar e inferir comportamientos, preferencias y patrones de uso a lo largo del tiempo.
Desde un enfoque técnico y sociotecnológico, la huella digital puede entenderse como un registro distribuido y persistente de interacciones, almacenado en múltiples capas —navegadores, plataformas, dispositivos, intermediarios publicitarios y bases de datos de terceros— cuya gestión y retención suelen estar definidas por políticas técnicas, comerciales o regulatorias que el usuario rara vez controla de forma directa.
Huella activa y huella pasiva: producción consciente e inconsciente de datos
La literatura especializada distingue entre huella digital activa y huella digital pasiva. La huella activa está compuesta por los datos que una persona genera de forma intencional: publicaciones en redes sociales, comentarios, formularios completados, correos enviados o archivos subidos a plataformas. Estos datos suelen estar asociados a una acción explícita y consciente del usuario.
Por el contrario, la huella pasiva se produce sin una intervención directa o plenamente consciente. Incluye búsquedas realizadas, clics, desplazamientos del cursor, tiempos de permanencia en una página, patrones de navegación y datos técnicos como direcciones IP o configuraciones del dispositivo. Aunque menos visibles, estos rastros son especialmente valiosos para sistemas de análisis y perfilado, ya que permiten observar comportamientos reales más allá del discurso explícito del usuario.
Esta distinción es clave porque gran parte de la información utilizada para perfilar a una persona proviene precisamente de la huella pasiva, no de aquello que el usuario decide comunicar de manera abierta.
Cookies, algoritmos y dispositivos: la infraestructura de la recolección de datos
La recopilación sistemática de huellas digitales se apoya en una infraestructura técnica compleja. Entre sus componentes más relevantes se encuentran las cookies, los identificadores persistentes y los sistemas algorítmicos de análisis de datos. Las cookies —especialmente las de terceros— permiten rastrear la actividad de un usuario a través de múltiples sitios web, asociando sesiones, preferencias y comportamientos a un mismo identificador digital.
A esto se suman los algoritmos de aprendizaje automático, que procesan grandes volúmenes de datos para detectar patrones, correlaciones y probabilidades. Estos sistemas no solo registran lo que hace un usuario, sino que generan modelos predictivos sobre lo que podría hacer, comprar o consumir en el futuro.
En la actualidad, los dispositivos también desempeñan un papel central. Teléfonos inteligentes, ordenadores y dispositivos conectados recopilan datos de sensores, ubicaciones aproximadas, configuraciones de red y hábitos de uso. Incluso cuando un usuario no inicia sesión, técnicas como el device fingerprinting (huella digital del dispositivo) permiten identificarlo a partir de combinaciones únicas de características técnicas.
Correlación de datos: cuando lo irrelevante deja de serlo
Uno de los aspectos más problemáticos de la huella digital es la capacidad de correlación de datos aparentemente irrelevantes. Información fragmentaria —como horarios de conexión, frecuencia de uso de una aplicación o tipos de contenido visualizado— adquiere significado no por su valor individual, sino por la forma en que es agregada, cruzada y analizada por sistemas algorítmicos, lo que permite inferir atributos sensibles como nivel socioeconómico, afinidades políticas o incluso estado de salud.
Datos que persisten en el tiempo
Aunque muchas plataformas ofrecen opciones para eliminar contenidos o cuentas, la persistencia del rastro es uno de los rasgos estructurales del entorno digital. Borrar un dato de una interfaz no implica necesariamente su eliminación de copias de seguridad, bases de datos secundarias, registros de terceros o sistemas de análisis históricos.
Además, algunos datos —como registros de acceso, transacciones o metadatos— están sujetos a obligaciones legales de conservación o a políticas internas de retención, lo que limita la capacidad real del usuario para hacerlos desaparecer por completo. En este sentido, la huella digital no es solo acumulativa, sino también asimétrica: el usuario tiene un control limitado sobre su ciclo de vida.
3 El valor de la identidad: datos como activo económico y herramienta de control
La identidad digital se ha transformado en un recurso estratégico central de la economía digital. Ya no cumple únicamente la función de identificar a una persona, sino que actúa como un mecanismo de agregación de datos que permite vincular comportamientos, historiales y atributos a un mismo sujeto a lo largo del tiempo. Esta persistencia convierte a la identidad en una infraestructura clave para mercados, plataformas y Estados, al facilitar la evaluación de riesgos, la asignación de confianza y la automatización de decisiones a gran escala.
El valor económico de la identidad digital se materializa a través de múltiples formas de monetización directa e indirecta de los datos personales. En algunos casos, los datos se comercializan explícitamente mediante intermediarios especializados; en otros, se utilizan para alimentar modelos predictivos que optimizan publicidad, precios, contenidos o decisiones automatizadas.
En este esquema, la identidad funciona como el eje que permite transformar datos dispersos en perfiles coherentes y explotables, incluso cuando el usuario no percibe una transacción económica directa.
Riesgos asociados y advertencia cypherpunk
Más allá del mercado publicitario, la identidad digital opera como una llave de acceso estructural a servicios esenciales. Sistemas de crédito, procesos de selección laboral, plataformas de salud y servicios públicos dependen cada vez más de identidades verificables y de los datos asociados a ellas. Esto convierte a la identidad en un prerrequisito para participar plenamente en la vida económica y social, al tiempo que amplía el impacto de errores, exclusiones o sesgos incorporados en los sistemas que la gestionan.
La concentración de datos identitarios también conlleva riesgos significativos. Entre los más documentados se encuentran la vigilancia sistemática, la discriminación algorítmica y la pérdida progresiva de autonomía individual. Cuando las decisiones se automatizan a partir de perfiles identitarios, los individuos pueden verse clasificados, limitados o penalizados sin transparencia ni mecanismos efectivos de impugnación, consolidando asimetrías de poder entre quienes controlan los sistemas y quienes son evaluados por ellos.
Estos riesgos no pasaron inadvertidos para los cypherpunks, quienes ya en los años 90 advirtieron que una identidad digital centralizada podía convertirse en una herramienta de control más que de emancipación. Desde esta perspectiva, la privacidad y la autonomía solo podían preservarse mediante sistemas criptográficos que limitaran la exposición identitaria y redujeran la necesidad de confianza en intermediarios. Muchas de las preocupaciones actuales sobre vigilancia y explotación de datos reflejan, décadas después, aquellas advertencias tempranas.

¿Quiénes fueron los cypherpunks?
Los cypherpunks fueron un movimiento de activistas, criptógrafos y programadores que surgió a finales de los años 80 y principios de los 90, centrado en la defensa de la privacidad y la libertad individual en el entorno digital. A través del uso de criptografía, promovieron la idea de que la protección frente a la vigilancia estatal y corporativa no debía depender de leyes o intermediarios, sino de herramientas técnicas. Sus ideas, difundidas en foros y listas de correo, anticiparon muchos de los debates actuales sobre identidad digital, vigilancia y control de datos, e influyeron directamente en el desarrollo de tecnologías como el cifrado moderno, el dinero digital y, décadas después, Bitcoin.
4 ¿Quién controla nuestra identidad digital hoy?
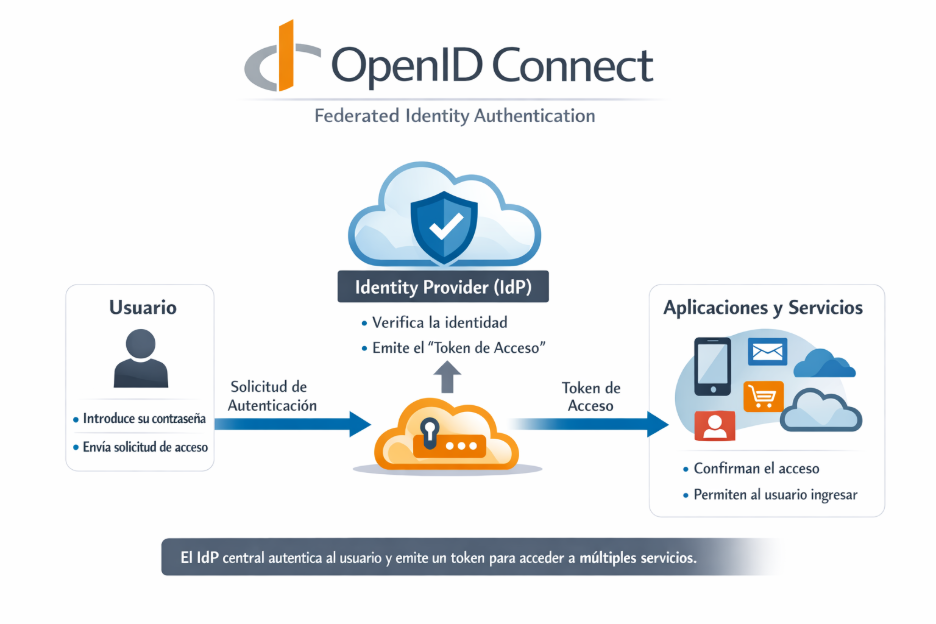
En la actualidad, la identidad digital está controlada principalmente por una combinación de plataformas tecnológicas privadas, Estados y proveedores de servicios que actúan como custodios de credenciales, atributos y accesos del usuario. Las grandes empresas tecnológicas operan como Identity Providers o proveedores de identidad (IdP) al centralizar la autenticación y autorización de usuarios en una vasta gama de servicios (correo, redes sociales, aplicaciones empresariales y comercio electrónico), con implicaciones directas en la privacidad, seguridad y gobernanza de los datos personales.
Este dominio también se extiende a gobiernos y organismos públicos que emiten identificadores electrónicos nacionales para acceder a servicios digitales estatales y privados en algunos marcos regulatorios.
Filtraciones de datos en sistemas centralizados: precedentes relevantes
Empresas como LinkedIn (2012) y Facebook-Cambridge Analytica (2018) mostraron los riesgos de concentrar información personal. En LinkedIn, millones de contraseñas fueron expuestas; en Facebook, datos de usuarios se usaron con fines de perfilado sin consentimiento claro. Estos casos evidencian cómo los sistemas centralizados pueden ser vulnerables tanto a fallas de seguridad como a abusos estructurales.
Los modelos actuales de autenticación y verificación de identidad descansan en arquitecturas centralizadas o federadas que dependen de contraseñas, tokens, certificados y protocolos estandarizados de acceso. Por ejemplo, OpenID Connect habilita la verificación de identidades en distintos servicios mediante un IdP externo que autentica al usuario en nombre de múltiples aplicaciones, reduciendo fricción, pero concentrando control en intermediarios específicos.
Un caso habitual de este esquema ocurre cuando una persona inicia sesión en un servicio utilizando su cuenta de Google o Facebook, lo que reduce fricción en el acceso, pero concentra el control de la autenticación en intermediarios específicos.
Otros mecanismos robustos incluyen la autenticación multifactor (MFA) y los estándares descentralizados como WebAuthn/FIDO2, que buscan mitigar la dependencia de contraseñas tradicionales y, al mismo tiempo, reforzar la seguridad del proceso de autenticación, reduciendo en algunos casos la concentración de control en intermediarios específicos.
Inconvenientes del control centralizado de datos
Este paradigma de control centralizado presenta problemas estructurales significativos. Al depender de una única entidad o base de datos para gestionar credenciales y atributos, se genera un punto único de falla vulnerable a brechas de seguridad, abuso de poder, censura o explotación comercial de datos. Estos sistemas restringen la soberanía del usuario al obligarlo a confiar en terceros para autenticar y administrar su identidad. Además, las filtraciones de datos centralizados han sido un vector recurrente de robo masivo de información personal.
En este esquema, el usuario actúa más como un sujeto de datos que como el propietario de su propia identidad. Aunque accede a servicios digitales mediante credenciales verificadas, raramente controla plenamente cómo se almacenan, utilizan o reutilizan sus datos personales. Los términos de servicio y políticas de privacidad de las plataformas suelen otorgar a los proveedores amplias licencias para recopilar, analizar y monetizar datos del usuario, así como para compartirlos con terceros bajo cláusulas amplias de consentimiento.
5 El futuro de la identidad digital: hacia modelos centrados en la persona
En contraste con los modelos actuales —centralizados o federados— donde grandes plataformas, Estados o intermediarios concentran la gestión de nuestras credenciales y atributos, el futuro de la identidad digital apunta hacia enfoques centrados en la persona, empoderando al individuo como protagonista de su propia representación en línea.
Una de las propuestas más sólidas y en expansión es la Identidad Auto‑Soberana (Self‑Sovereign Identity, SSI). Este modelo reconoce que el individuo debe poseer y controlar su identidad sin depender de autoridades administrativas o plataformas centralizadas. La SSI permite a las personas decidir qué datos compartir, con quién y bajo qué condiciones, reduciendo así la exposición no deseada de su información personal y mitigando riesgos como la vigilancia excesiva o la explotación comercial de datos.
Tecnológicamente, este enfoque se apoya en identificadores descentralizados (DIDs) y credenciales verificables (VCs) que funcionan sin intermediarios repetidos, facilitando comprobaciones de identidad directas entre quien presenta una credencial y quien la verifica.
Principios de soberanía, portabilidad y consentimiento informado
Los sistemas centrados en la persona se fundamentan en una serie de principios rectores que buscan devolver el poder al usuario:
- Soberanía y control: los individuos son la máxima autoridad sobre su identidad, gestionando su información sin que terceros la posean por defecto.
- Acceso y portabilidad: los usuarios pueden acceder a sus datos en cualquier momento y trasladarlos entre servicios o dispositivos a su elección.
- Consentimiento informado y divulgación mínima: cualquier uso o intercambio de datos solo ocurre con consentimiento explícito y debería limitarse a los datos estrictamente necesarios para la transacción correspondiente.
- Interoperabilidad y transparencia: los ecosistemas de identidad deben funcionar con estándares abiertos, permitiendo verificación y uso entre distintos sistemas sin fricciones.
Tecnologías emergentes aplicadas a la identidad
Varias tecnologías están impulsando este cambio:
- Credenciales Verificables (Verifiable Credentials, VCs): son certificados digitales emitidos por entidades confiables (como universidades o gobiernos) que el usuario guarda en su billetera digital y presenta según necesidad, con prueba criptográfica de validez.
- Identificadores Descentralizados (DIDs): funcionan como una base para representar a personas u organizaciones sin dependencia de autoridad central, facilitando autenticaciones seguras y privadas.
- Pruebas de conocimiento cero (ZeroKnowledge Proofs): permiten demostrar que se cumple un criterio (por ejemplo, tener más de cierta edad) sin revelar datos personales concretos, reforzando el principio de divulgación mínima.
- Wallets de identidad: aplicaciones seguras que almacenan credenciales y claves del usuario, habilitando interacción con servicios sin intermediarios repetidos.
Desafíos éticos, técnicos y sociales de estos modelos
Los enfoques centrados en la persona, aunque prometedores, enfrentan diversos desafíos antes de una adopción masiva. En el plano técnico, la gestión de claves privadas y la recuperación de identidad en caso de pérdida constituyen retos aún no completamente resueltos. La infraestructura criptográfica y los estándares para identidades descentralizadas siguen en evolución, y lograr interoperabilidad plena entre distintos sistemas requiere coordinación internacional, además de asegurar la robustez y seguridad de los protocolos subyacentes.
Desde una perspectiva ética, es necesario garantizar que los sistemas de identidad autosoberana se diseñen de manera que no se conviertan en nuevas formas de control, como podría suceder mediante mecanismos de reputación estandarizada que clasifiquen o penalicen a los usuarios. Para ello, se requieren marcos normativos sólidos y la participación activa de la sociedad en la gobernanza de estas tecnologías, de manera que se protejan los derechos de los individuos y se preserve la autonomía personal.
Los desafíos sociales y de adopción también son significativos. La complejidad técnica de los sistemas, la falta de confianza pública en tecnologías emergentes y las barreras de alfabetización digital pueden limitar la aceptación inicial, especialmente entre poblaciones vulnerables o con menor acceso a recursos tecnológicos. Sin una adecuada educación digital y estrategias de inclusión, la transición hacia modelos centrados en la persona podría profundizar desigualdades existentes en lugar de resolverlas.

